고정 헤더 영역
상세 컨텐츠
본문 제목
[Paper review] A Style-Based Generator Architecture for Generative Adversarial Networks
본문
이번 논문은 'Style GAN'이라고 잘 알려진 모델이 처음 소개된 논문이다. 논문의 introduction에서는 Traditional GAN의 'Black box' 적인 한계를 지적하면서 시작한다. 여기서 'Black box'란, Traditional GAN은 image를 generation함에 있어서, 어떤 스타일, 형태의 이미지가 생성될 것인지 예측할 수 없게 작동했다는 의미이다. 논문에서 제시하는 Style GAN은 이러한 한계를 극복한 모델로써, 사용자가 image synthesis process를 컨트롤 할 수 있는 모델로써 소개된다.
이번 리뷰에서는 Style GAN의 구조적인 특징을 중심으로 어떻게 한계를 극복했는지 살펴볼 것이다.
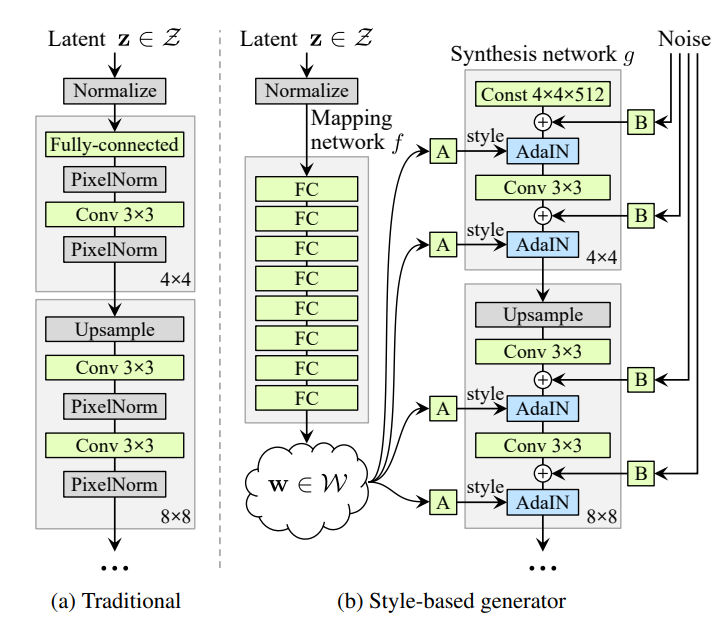
위 사진의 왼쪽은 Traditional GAN의 구조를 나타낸것이고, 오른쪽은 Style GAN의 구조이다. 참고로 논문에서도 언급했지만, Style GAN은 Traditional GAN의 Generator 구조만 바꾼 모델이다. 나머지 loss function이나 Discriminator는 동일하다.
Style GAN의 차별적인 구조는 3가지로 요약될 수 있다.
첫번째, Intermediate latent space이다.
위 그림에서 보면 traditional GAN이 latent vector z를 곧바로 generator에 넣어주는 것과 달리, Style GAN에서는 FC layers를 거친 후에 새로운 latent vector, w를 만들어 낸다는 것을 볼 수 있다. 이렇게 latent space를 그대로 사용하는 것이 아니라 mapping function을 통해 intermediate lantent space로 보내주면, 모델이 훈련 이미지에 드러난 특징들을 disentangle한 학습하게금 만든다고 한다. (disentangle = 이미지의 feature(머리스타일, 안경..etc)가 서로 얽혀져있지 않고 linear하게 분포된 것을 의미) 이게 어떻게 가능할까?
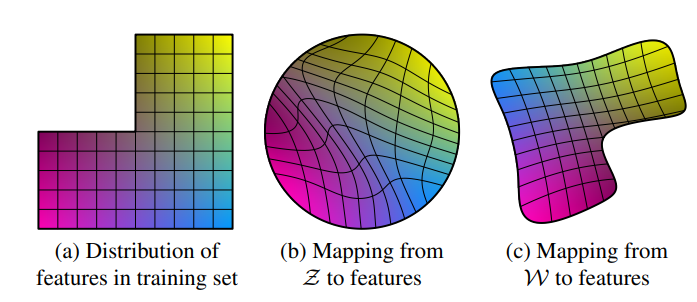
위 그림을 보면 쉽게 이해를 할 수 있다. (a)가 훈련 이미지들의 특징 분포라고 하면, traditional GAN 과 같이 latent vetor를 곧바로 넣어줄 경우, latent space 속 vetor들의 분포가 curved(entangle)하게 변하게 된다. 하지만, mapping function을 통해 훈련 이미지의 특징 분포와 비슷한 latent space로 만들면, linear(disentangle)하게 만들어진다.
두번째, AdaIN을 통한 스타일 주입이다.
Intermediate latent vetor, w는 affine transfomation을 거침으로써, style(ys, yb)로 변하게 되고, Synthesis network의 feature map(x)과 AdaIN 연산을 하게 된다.

AdaIN 연산은 feature map을 normalization한 후에, style을 적용하는 방식이다. 여기서 핵심은 normalization인데, 이러한 과정을 통해 style이 전체 이미지에 global한 effect를 줄 수 있게 한다고 설명한다. 여기서 global한 effect는 changing pose, identity 등을 말한다. 추가로, 이러한 AdaIN 연산은 네트워크에서 합성곱이 연산이 끝난 후 마다 들어가는 것을 볼 수 있는데, 이렇게 style을 여러 layer에서 분리해서 넣어줌으로써, 사용자가 style을 local 하게 컨트롤 할 수 있게금 만들 수 있게 된다.
마지막으로, noise 주입이다.
스타일 주입과 별개로, Style GAN에서는 noise를 넣어준다. 이러한 noise 주입의 역할은 stochastic variation을 모델이 학습하기 위함이다. stochastic variation은 쉽게 말해, 미세한 이미지의 특징을 말한다. 예를 들면 헤어스타일에서 curl의 정도, background의 detail 등이다. noise 역시 AdaIN 연산과 마찬가지로, 합성곱 연산이 끝난 후 마다 들어가고, 비슷한 효과를 기대한다.
지금까지 Style GAN의 구조를 살펴봤다.

위 그림을 보면 알 수 있듯이, Traditional GAN에 비해 성능이 좋은 것을 알 수 있다. 하지만 Style GAN의 성능은 위에서 단순히 보이는 수치보다, 'Image generation에 있어서 Black Box 현상' 을 줄인 것을 주목해야 한다. 즉, 사용자가 원하는 Style, variation을 주입한 이미지들을 기호에 맞게 생성할 수 있게되었다는 것이다.
이번 논문을 읽으면서 개인적으로 Style GAN은 latent vector에 대한 깊은 이해를 바탕으로 만들어졌다는 모델이라는 것을 느꼈다. 특히 input으로써 latent vector의 역할을 넘어서, 훈련 이미지의 다양한 style 역할로써 latent vector를 사용한 idea는 이후 다양한 Generative model에서 사용되는 idea라는 점에서 더욱 유심히 보았던 것 같다.
논문에서는 이 글에서 설명한 내용외에도, Style Mixing을 통한 훈련시 regularization 기법, Image generation 새로운 평가지표 Peceptual path length, Linear seperability 등 다양한 내용을 담고 있다. 관심있으면 아래 링크를 참조 바란다.
https://arxiv.org/abs/1812.04948
A Style-Based Generator Architecture for Generative Adversarial Networks
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identit
arxiv.org


댓글 영역