고정 헤더 영역
상세 컨텐츠
본문
오늘 리뷰할 논문에서 소개하는 모델은 DETR이다. DETR는 DEtection TRansfomer에서 알 수 있듯이, Transfomer을 활용해 Object Detection을 수행하는 모델이다. 최근 transfomer을 Computer Vision에 적용하는 동향에서 자연스럽게 나온 모델이라고 생각할 수 있다. DETR는 실제로 특정 task에서는 SOTA를 달성했고, 꽤나 강력한 모델이다. 모델의 가장 큰 특징은 'End-to-End' 모델이라는 점인데 즉, 파이프라인 네트워크 여러개를 이어서 하나의 큰 예측 시스템을 만드는 게 아니라, 입력 부터 출력까지 하나의 모델로써 작업을 한 번에(Directly) 처리하는 것을 말한다.

위 그림은 DETR의 구조를 표현한 그림이다. 그림에서는 가시성을 위해 모듈을 하나씩 구별했지만, 이 모듈이 모두 따로 처리되는 것이 아니라, 한 번에 처리된다. 즉, 이미지가 CNN backbone을 거쳐서 최종적으로, class와 bounding box까지예측하는 일련의 과정이 한번에 이루어지는 것이다. (End to End 방식)
DETR는 Transfomer의 구조를 활용한 모델이다.
그렇다면, 이제 모델의 구조를 하나씩 뜯어보면서 살펴보자. 이미지는 가장 먼저 CNN backbone을 거친다. backbone을 거치면서, resolution은 줄어들고 채널은 커진 activation map이 나오게 된다. 이러한 map은 1x1 convolution을 추가로 적용하여 채널의 수를 줄인 후, flatten 과정을 거친 뒤 'Positional Encoding'을 거치게 된다. 사실 이 과정은 놀랄게 없는게 기존의 Transfomer의 과정을 그대로 따라가는 것이다. 이후 Transfomer의 encoder를 지난 후, decoder를 지나게 된다. decoder에서는 encoder의 output과 더불어, 'object queries'를 input으로 받게 된다. 여기서 'object queries'는 학습된 N개의 positional embeddings를 가르킨다. 추가로, DERT의 transfomer decoder는 기존의 auto regressive 방식(순차적인 방식)으로 작동하는 original transfomer와 다르게 N개의 embeddings을 병렬적으로 처리한다. 나머지 구조는 동일하다. 최종적으로 decoder의 output은 prediction heads를 거친다. prediction head는 FFNs로 이루어져있고, class와 boundingbox를 에측하는 역할을 한다. decoder의 output 하나당 예측된 class, boundingbox가 나오게 된다.
이게 모델의 구조 끝이다. DETR는 Transfomer를 Detection 모델로써 쓴 것 외에는 구조적인 면에서는 단순하다.
최적의 matching을 구해 loss function을 계산한다.
이처럼 DETR에서 transfomer가 중요한 역할을 하지만, loss function 역시 큰 역할을 한다. DETR의 loss function은 set prediction loss를 사용한다. 예측하고자 하는 objects의 class와 bounding box의 후보를 많이 만들어 놓고, 실제 정답과의 차이를 가장 적게 보이는 쌍을 matching한 loss를 사용하는 것이다. 이해를 돕기 위해서 예를 들면, 실제 이미지에 정답으로 주어진 class-boundigbox 쌍이 10개 있다고 하자. DETR는 이러한 정답 후보가 될 수 있는 class-boundingbox 쌍을 최종적으로 N개(>>10) 예측한다. 결국 여기서 핵심은 모델이 예측한 N개의 후보들 중 정답에 가장 적합한 10개의 최적 matching을 찾아내는 것이다. 이를 판단하기 위한 기준으로, 다음과 같은 Lmatching을 사용한다. (p는 class 예측 확률이고, Lbox는 boundingbox loss로써, L1 loss와 iou loss의 linear combination로 표현된다.)

최적의 matching 해는 대표적인 matching 문제의 해법인 'Hungarian algorithms'을 통해 찾을 수 있다. 이렇게 구해진 최적의 matching쌍으로 부터 계산되는 loss가 DETR가 사용하는 loss 이다.
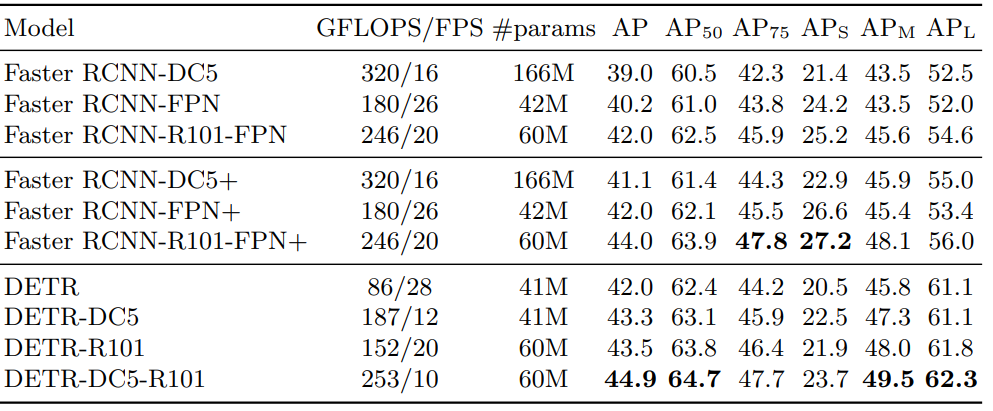
논문에서는 DETR의 성능에 대해서도 실험한 결과를 확인 할 수 있었다. 위 표를 보면 알 수 있듯이 큰사이즈와 중간사이즈의 object를 detection하는 task에서는 SOTA를 달성한 것을 알 수 있다. 하지만, 작은 사이즈의 object는 기존의 Faster RCNN 모델에 비해 좋지 않은 성능을 보인다는 것을 알 수 있다. 이것은 DETR의 한계이자 극복해야 할 과제이다.
이외에도 transfomer의 encoder와 decoder의 layer 개수를 늘리는 실험을 진행했고, 그 결과 성능이 더 좋아진다는 사실 역시 발견할 수 있었다.
추가로 panoptic segmentation에서도 DETR를 실험했는데, 특정 task에서 SOTA를 달성했다. 이는 DETR가 object detection외에도 다른 task에서도 잘 적용될 수 있다는 가능성을 보여준다.
이번 논문을 리뷰하면서, Transfomer의 활용가능성에 대해서 또 한번 놀랐고, DETR의 small object에 대해 부족한 성능을 나타내는 이유에 대해서도 고민해볼 수 있었다. 초기에 이미지의 feature를 추출하는 과정에서 단순히 backbone을 사용하는 것이 아니라 약간의 세밀한 작업이 필요할 수 있겠다는 생각이 들었다. 특히 이번논문에서는 loss function을 설명하는 과정이 더욱 흥미로웠는데, 우리과(산업경영공학부)에서 assignment problem을 다루면서 배웠던 Hungarian Algorithm이 활용되었기 때문이다. 우리과에서 배우는 최적화 이론들이 이렇게 Computer Vision의 최신 모델의 핵심적인 원리로써 적용되는것이 뿌듯한 느낌도 들었고, 동시에 나 역시 과에서 최적화 이론들을 잘 배워서 DETR처럼 좋은 모델을 만드는데 적용해보고 싶다는 생각이 들었다.
아래는 리뷰한 논문의 주소이다.
https://arxiv.org/abs/2005.12872
'Paper review' 카테고리의 다른 글
| [Paper review] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (0) | 2022.01.21 |
|---|---|
| [Paper review] Vision Transfomers for Dense Prediction (0) | 2022.01.18 |
| [Paper review] Mask R-CNN (0) | 2022.01.12 |
| [Paper review] MLP-Mixer An all-MLP Architecture for Vision (0) | 2022.01.08 |
| [Paper review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2022.01.06 |


댓글 영역