고정 헤더 영역
상세 컨텐츠
본문 제목
[Paper review] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
본문
우리가 살아가는 세상은 3D이다. 지금 옆에 있는 어떠한 물체든 한번 보자. 흥미롭게도 우리 인간은 어떤 물체의 일부분만을 봐도 그 물체의 나머지 형태가 어떨지 쉽게 추론할 수 있다. 가령 책상 위 물병을 본다고 생각하면, 우리는 현재 보고 있는 물병의 모습말고도 그 물병의 나머지 모습이 어떨지 추론할 수 있다. 그렇다면 이러한 인간의 능력을 컴퓨터가 할 수 있게 할 수는 없을까? 좀 더 들어가서 딥러닝(Neural Network)를 활용해서 이러한 능력을 구현할 수는 없을까?. 오늘 리뷰하고자 하는 모델, NeRF(Neural Radiance Fields) 역시 이러한 질문을 시작으로 탄생했다고 할 수 있다. 결론적으로 NeRF는 3D 물체에 대해서 특정 각도에서 찍은 사진만 있으면, 인간처럼 그 3D 물체의 나머지 부분들에 대해서 추론할 수 있는 모델이다. 어떻게 이게 가능할까? NeRF의 구조와 원리에 대해서 하나씩 파헤쳐 보면서 알아보자.

위 그림을 보면서 NeRF의 구조를 따라가보자. (a)를 보면 포크레인을 두 가지 각도에서 찍은 사진이 있다. (실제로는 더 많은 각도의 사진을 찍혀 있을 수 있다.) NeRF는 핵심은 물체를 특정 각도에서 찍은 이미지의 하나의 픽셀은 실제 물체를 이루는 여러지점의 Color와 Density로 이루어져있다는 생각에서 출발한다. 즉, 우리 어떤 방향에서 찍은 물체의 2D 이미지는 실제 3D 물체을 이루고 있는 여러지점의 Color와 Density로 이루어져 있다는 말이다. 가령 (a)를 보면 실제 3D 포크레인의 검은 색 point들의 Color와 Density가 모여서 특정 각도에서 찍은 이미지의 한 픽셀을 이루다는 것을 확인 할 수 있다. 여기서 모든 검은색 point들을 연속적으로 정의해서 픽셀 값을 추론하는 것이 가장 정확하지만, 현실적으로 이는 불가능하다. 결국 우리가 직접 2D 이미지의 한 픽셀 값을 이루는(위에서 화살표 위에 있는)point들을 Sampling하는 과정이 필요하다. (뒤에서 자세히 설명)
논문에서 Sampling한 point 각각은 5D input으로 표현한다. (x, y, z, 세타, 파이) 로말이다. 여기서 (x, y, z)는 실제 3D 물체를 이루는 point의 좌표를 말한다. 그리고 (세타, 파이)는 viewing point로, 우리가 이미지를 바라보는 각도(카메라의 각도)라고 생각하면 된다. 여기서, (x, y, z, 세타, 파이)의 값들은 실제로 어떻게 구할 수 있는지 궁금할 수있다. (난 처음에 이게 젤 궁금했다.) 이러한 작업은 초기에 카메라를 세팅해서 3D 물체를 찍을 때, 다 구할 수 있다고 한다.
이제 NeRF를 위한 input을 준비했다. 그 다음 작업은 앞서 말한 NeRF의 핵심인 이 point 각각이 가지는 Color와 Density를 구해야 한다. NeRF에서는 이 작업을 MLP가 수행한다. 위 그림에서 F(세타)가 이를 나타낸다.
NeRF는 Volume Rendering을 통해 최종적인 픽셀의 Color를 예측한다.
이제부터 2d 이미지의 한 픽셀을 예측하기 위한 준비물이 다 준비됐다. 위 그림에서 한 직선 위 검은색 point들에 해당하는 Color와 Density를 구한 상태이다. 이제 남은 작업은 이 검은색 point들이 가지는 값들을 조합해서, 2d 이미지의 픽셀의 Color를 구해야 한다. 여기서 NeRF는 'Volume Rendering' 을 사용한다.
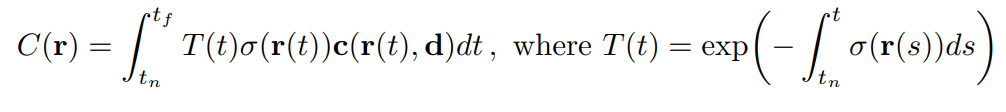
위 식이 Volume Rendering 기본 계산식이다. 좌변의 C(r)이 우리가 최종적으로 구하고자 하는 픽셀의 Color라 생각하면 된다. 정적분의 구간을 보면 tn에서 tf로 되어있는데, 이 값은 우리가 초기에 정해주는 값으로, 픽셀의 Color를 예측을 위한 point들이 존재할 수 있는 구간을 의미한다. 시그마(r(t))는 앞서 구한 Density를, c(r(t), d)는 Color를 의미한다. T(t)는 accumulated transmittance로 누적된 투과율로써, 특정 point 앞에 여러 점이 존재하면 픽셀을 color에 기여하는 그 점의 Density나 Color의 강도가 줄어드는 효과를 반영하기 위해 만든 term이라 생각하면 된다.
여기서 눈치챘을 수도 있지만, 위 계산식은 point들이 연속적으로 정의된 상태에서 쓸 수 밖에 없다. 하지만 우리는 point들을 sampling해서 사용한다. 따라서 위 식이 아닌 아래와 같이 근사한 식을 사용한다.
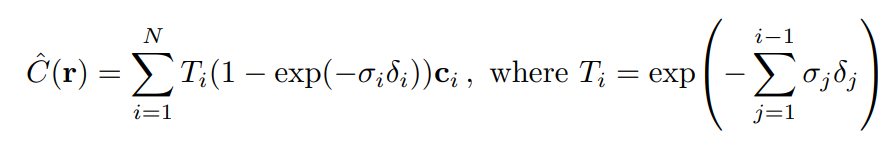
위 정적분 식과 하나씩 비교해보면, 각 term이 가지는 의미는 완전히 동일하다.
이렇게 Volume Rendering 과정을 거치게 되면 우리는 이미지 하나의 픽셀이 가지는 Color를 예측 할 수 있다. 이제 이 예측값과 실제 픽셀값을 비교하면 loss를 구하면 끝이다. 논문에서는 loss는 L2loss를 사용한다고 한다.
지금까지 NeRF가 기본적으로 어떻게 작동하는지 알았을 것이다. 논문에서는 이러한 구조를 가진 NeRF를 최적화하기 위한 다양한 방법론들을 추가로 소개한다. 첫번째는 Positional Encoding이다. 5d input을 바로 MLP에 집어 넣는 것이 아니라, high dimension으로 보내는 과정이다. 이러한 과정을 포함함으로써, 3D 물체의 미세한 부분까지도 섬세하게 에측할 수 있게 된다. 두번째는 Hierarchical Volume sampling이다. 계속 언급하지만 우리는 픽셀의 Color를 예측하기 위해, 몇몇 point들을 sampling해서 사용한다. 이 과정에 대해 자세히 설명하면, 특정 구간을 동일하게 나누고 각 구간내에서 하나씩 sampling하는 Stratified Sampling을 사용한다. 이러한 sampling 기법을 사용할 경우, sampling할때, 실제 픽셀 Color와 관련없는 부분만이 예측되는 문제가 생긴다. 논문에서는 이를 해결하기 위해, Hierarchical Volume Sampling을 소개한다.
NeRF는 Coarse Network 와 Fine Network를 통해 훈련된다.
Hirerarchical, 말그대로 계층적으로 sampling한다는 뜻이다. 즉 중요한 sample 위주로 뽑겠다는 것이다. 이를 판단하기 위한 기준으로 기본적으로 Stratified Sampling을 통해 추출된 point들의 density 정보를 활용한다. 즉 density가 높은 point 근처에 있을수록, 중요한 sampling이 존재한다고 생각하고 추출하는 방법이 Hierarchical Volume Sampling인 것이다. (수학적으로, inverse transform sampling을 사용)
여기서 결국 모델은 두개의 네트워크로 학습해야 한다는 것을 판단할 수 있다. 먼저 Stratified Sampling을 통한 학습 네트워크, 그리고 이 네트워크에서 예측한 point들의 density를 가지고 Hierarchical Volume Sampling을 통한 학습 네트워크 이렇게 말이다. 전자를 Coarse Network라 하고 후자를 Fine Network라 한다. 참고로 Fine Network에서는 Stratified Sampling을 통해 추출한 sample까지도 학습에 활용한다. NeRF의 최종적인 loss는 이 두 Network에서 각각 예측한 픽셀 color와 실제 픽셀 color를 통해 계산된 L2loss의 합으로 정의된다.

NeRF는 위 결과에서 알 수 있듯이, 거의 모든 지표에서 SOTA를 달성한 것을 알 수 있다.
논문의 마지막부분에서는 NeRF와 관련된 후속 연구에 대한 방향성을 언급한다. 하나는 Sampling strategy, 즉 sampling에 있어서 더 효과적인 방법이 없을까라는 방향성이다. 그리고 나머지 하나는 Interpretability로, MLP를 사용하기 때문에 모델 결과 분석에 있어서 unclear한 문제이다.
지금까지 NeRF를 리뷰했다. 다소 이전 리뷰에 비해 긴 경향이 있다. 하지만 NeRF는 3D Vision 분야에서 요즘 가장 핫하고 기본적인 모델이다. 그만큼 어마무시하게 중요한 모델이다.
난 이번 논문을 읽기전에는 어떻게 신경망을 이용해, 3D 물체를 예측할 수 있을까라는 생각이 들었지만, NeRF를 통해 대략적인 감을 잡을 수 있었다. 이와 더불어 사람이 보는 세상이 3D인 만큼, 이 분야에 대한 연구가 더 흥미롭게 다가왔고 NeRF에 대한 후속연구도 궁금했다. 마지막으로 이렇게 NeRF로써 복잡하게 구현하는 능력을 태어날때 부터 가지고 있는 사람의 시각에 다시한번 놀란다.
아래는 논문 링크이다.
https://arxiv.org/abs/2003.08934
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views. Our algorithm represents a scene using a fully-con
arxiv.org


댓글 영역