고정 헤더 영역
상세 컨텐츠
본문
오늘은 많은 사람들이 알만한 논문하나를 리뷰하고자 한다. 바로 'Attention Is All You Need'라는 논문이다. 이 논문은 우리가 익히 아는 'Transfomer'의 시초가 되는 논문이다. 이미 블로그에서 Vision Transfomer, DETR 등 Transfomer 기반의 모델 관련 논문들을 여러차례 리뷰했지만, 이들의 시초가 되는 논문 역시 리뷰를 하면서 정리를 할 필요가 있다고 느꼈다.
Transfomer가 처음 등장했을때, 이 모델은 자연어처리, 그 중에서도 Translation Task을 위해 나온 모델이라고 해도 과언이 아니다. (실제로 논문에서도 Translation task에서만 Transfomer를 시험했다는 것을 알 수 있다.) Transfomer는 이후 BeRT, GPT 등에 직접적으로 활용되면서 그 성능이 증명되었고, 요근래(2022년) 기준으로도 Translation 부분에서 활약하고 있는 거의 대다수의 모델이 Transfomer 기반의 모델이다.
Transfomer의 핵심 아이디어는 논문제목에서도 나와있듯이, Attention이라는 개념이다. Attention 개념은 이 논문에서 처음으로 제시한 아이디어는 아니다. 기존 모델들, 가령 RNN, LSTM 기반의 Seq2Seq 모델들에서도 두루 활용되었다. 그러나 이러한 모델들의 한계는 기본적으로 하나의 단어씩 순차적으로 연산해야만 했기에, 계산시간이 매우 오래걸린다는 점이었다. 이에 반해 Transfomer는 RNN과 같은 모듈을 쓰지않고 Attention의 개념만으로 모델을 구성하였고, 하나의 문장 전체를 입력으로 받아 한꺼번에 병렬적으로 처리할 수 있는 모델이다. 이는 GPU를 효과적으로 사용할 수 있는 모델이라는 뜻이기도 하다. 성능 역시 기존 모델들을 뛰어넘는 것을 보여준다. 그렇다면 Transfomer는 구체적으로 어떤 구조와 방법을 통해 Attention 개념만으로 모델을 만들어 낼 수 있었을까?

위 그림은 Transfomer의 전체 구조를 나타낸 것이다. 논문에서 Transfomer는 Translation을 위한 모델로써 소개되었기 때문에 구조는 크게 Seq2Seq 모델, Encoder(위 그림에서 왼쪽)와 Decoder(위 그림에서 오른쪽)으로 이루어져 있다는 것을 알 수 있다. 참고로 위 그림에서는 Encoder, Decoder 모두 layer 하나에 해당하는 그림만 표현되어있는데, 실제로는 똑같은 구조의 layer을 N개씩 사용한다.
그림에서는 Multi-Head Attention이라는 모듈이 가장 눈에 뛴다. Attention도 헷갈리는 데, Multi-Head Attention은 무엇일까? 논문에서 소개한 식을 통해 이해해보자.
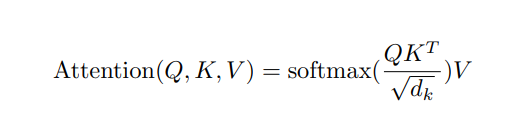
먼저 Attention의 개념부터 설명해보겠다. 위 식에서 Q는 Query라 하고, K는 Key라고 하고, V는 Value라 한다. 참고로 여기서 Key와 Value는 한쌍이라 생각하면 편하고, 우리가 Attention을 통해 최종적으로 구하고자 하는 것은 Query가 가져야 하는 값이다. 따라서 Attention을 한마디로 하면 "Query와 Key와의 비교를 통해, Query가 가져야 하는 값을 찾는 과정" 이라고 할 수 있다. 위 식에서 Query와 Key의 비교가 둘의 행렬곱해주는 부분이다. 루트 dk로 나눠주는 것은 스케일을 조정해주기 위함이다. 여기까지를 Attention의 Energy를 구한 과정이라고 한다. Energy를 구한 후엔 Softmax를 거치는데, 이 과정까지 거치게 되면 Query의 특정 부분이 Key를 이루는 모든 부분들에 대해서 대응되는지 비율이 나타나게 된다. (비율이 높을 수록 더 크게 대응되는 부분이라는 뜻이다.) 마지막으로 Key의 Value값을 곱해 줌으로써, 최종적으로 Query가 가져야 하는 값을 구할 수 있게 된다.
이제 Attention의 기본개념을 알았으니, Multi-Head Attention에 대해서도 알아보자.
Trasfomer의 핵심 모듈은 Multi-Head Attention이다.

논문에서는 위 식을 통해 Multi-Head Attention을 설명한다. 이를 설명하면, 위에서 설명한 Attention을 여러 head에서 실행한 후, concat을 함으로써 이들을 합쳐준다는 뜻이다. 한마디로 Attention을 한번에 그치는 것이 아니라 여러 임베딩 space 상에서 수행하는 개념이다. 이렇게 하면, 모델이 다양한 Attention의 컨셉을 가지고 갈 수 있다는 장점이 있다. 가령 우리 어떤 문장을 번역을 할때, 특정 단어가 대응되어야 하는 부분이 문장의 한 곳만 있는 것이 아니라, 다양하게 방식으로 포진되어있다. Muti-Head Attention은 이러한 특성을 잘 반영할 수 있는 Attention의 개념인 것이다. (상식적으로도 한번만 Attention하는 것보다는 좋을 것이다.)
이제 Multi-Head Attention을 이해했으니, Transfomer의 구조는 보다 쉽게 이해될 것이다.
하나씩 보면, Encoder의 Multi-Head Attention은 Self-Attention으로 앞서 Attention에서 말한 Q, K, V가 전부 같은 값이다. 약간 어리둥절할 수 있지만, Encoder에서는 아직까지 input으로 받은 문장밖에 없는 상태이기 때문에 이 문장 안에 있는 단어들 사이의 대응관계를 파악해야만 한다. 따라서 3개의 값을 모두 같은 값을 쓰는 것이다.
이와 다르게 Decoder의 Multi-Head Attention은 Encoder처럼 Self-Attention의 개념을 사용하는 'Masked Multi-Head Attention' 모듈과 일반적인 Attention의 개념을 사용하는 Multi-Head Attention 모듈 이렇게 2가지 방식이 존재한다. 전자의 경우, Encoder와 마찬가지로 Decoder로 입력 받은 문장 안에 있는 단어들 사이의 대응관계를 파악하기 위함이다. 참고로 Masked라는 게 붙은 이유는 문장을 번역할때, auto-regressive 방식(Decoder의 단어를 번역할때, 그 단어는 그전까지 나온 단어들만을 고려해야 하는 방식)을 구현하기 위해 Attention Energy를 Masking 해야하기 때문이다.
후자의 경우, Query로는 Decoder에서 진행되고 있는 값을 사용하고, Key와 Value로는 Encoder의 출력값을 넘겨받음으로써, Decoder에서 문장을 뽑아낼때, Encoder의 문장 중 어떤 단어들을 Attention해야할지 파악하기 위함이다.
추가적으로 모델 그림에서 Feed Foward와 Add&Norm은 특별한게 아니라, MLP블록, Residual 방식&LayerNorm을 각각 표현한 것이다.
Trasfomer의 또다른 핵심 모듈은 Positional Encoding이다.
Transfomer는 Multi-Head Attention도 중요하지만 한가지 더 중요한 모듈이 있다. 그건 바로 'Positional Encoding' 이다. Transfomer의 핵심은 하나의 단어를 순차적으로 처리하는 RNN방식과 다르게 문장 전체를 한번에 input으로 받기 때문에 모델이 문장을 이루는 단어들이 초기에 어떤 위치에 있었는지 알 필요가 있다. Positional Encoding은 이를 위해 필요한 모듈이다. 모델(Encoder, Decoder)에 입력된 문장의 단어들은 Embedding을 거친 후, Positional Encoding을 통해 문장에서 자신의 위치가 어딘지 부여받게 된다. 특히 논문에서는 아래와 같이 주기함수를 이용한 방법을 소개한다.

지금까지 Transfomer의 핵심적인 구조에 대해서 알아보았다. 리뷰 제일 초반에도 잠깐 말했듯이 Transfomer는 Translation에서 SOTA를 달성함과 동시에, GPU를 활용해 효율적으로 움직일 수 있다.
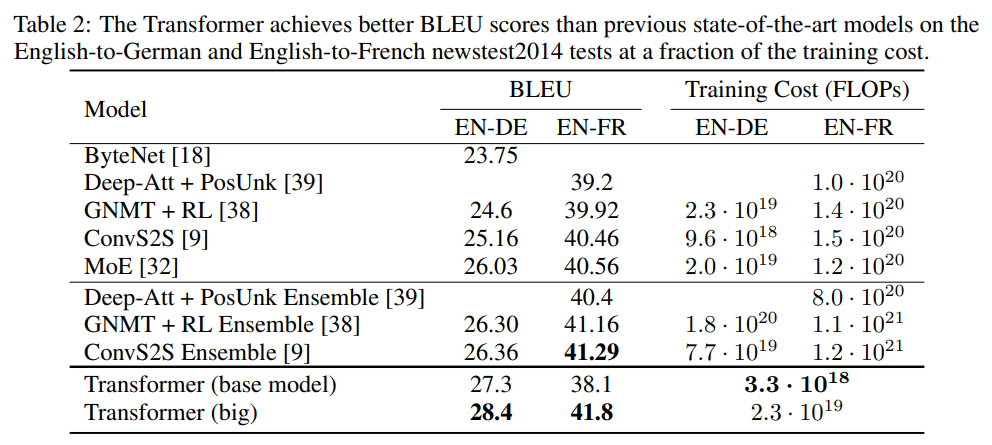
위 표를 보면 쉽게 이해할 수 있다. (여기서 EN-DE는 영어-독일어 번역을 말하고, EN-FR은 영어-프랑스 번역을 말한다.)
BLEU score 기준으로 SOTA를 달성함과 동시에, 기존 모델들과 비교했을때, Training Cost 역시 작은 것을 알 수 있다.
오늘은 Attention의 개념과 더불어 Transfomer의 시초 논문에 대해서 리뷰에 보았다. 이 논문은 이후 많은 모델들의 기초가 되는 논문이기에 보다 자세하고 확실하게 이해하길 바란다. 필자도 포스팅을 쓰면서 다시한번 Attention과 Transfomer의 구조에 대해서 복습한 것 같다.
아래 링크는 차례대로 논문링크, Transfomer 코드 구현링크, Transfomer을 공부하기 좋은 유튜브 영상이다.(나동빈 연구원님 영상)
참고하길 바란다.
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
https://github.com/ChoiDae1/Transfomer-PyTorch/blob/main/Implementing_Transfomer.ipynb
GitHub - ChoiDae1/Transfomer-PyTorch: Implementing Transfomer by PyTorch(in Colab)
Implementing Transfomer by PyTorch(in Colab). Contribute to ChoiDae1/Transfomer-PyTorch development by creating an account on GitHub.
github.com
https://www.youtube.com/watch?v=AA621UofTUA


댓글 영역