고정 헤더 영역
상세 컨텐츠
본문
이 블로그의 첫 번째 paper review는 제목에도 나타 있듯이 'Style transfer'에 관한 논문을 하려고 한다. 최근에 '파이토치 첫걸음'이라는 책을 사서 독학으로 공부하고 있는 도중, 우연히 이 논문에 대해서 접할 수 있었다. 책에서 이와 관련해 요약하여 내용을 전달하고 있었지만 읽으면서, '어떤 이미지에 다른 이미지의 스타일을 입혀서 만들어내는 점'에서 재밌을 것 같아서 논문까지 찾아서 읽게 되었다.
논문을 본격적으로 리뷰하기 전, 이 논문은 CVPR 2016에 등재된 논문으로, 책에서도 Style transfer의 시초가 되는 논문이라고 소개한다.
(링크)-> https://openaccess.thecvf.com/content_cvpr_2016/html/Gatys_Image_Style_Transfer_CVPR_2016_paper.html
CVPR 2016 Open Access Repository
Leon A. Gatys, Alexander S. Ecker, Matthias Bethge; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2414-2423 Rendering the semantic content of an image in different styles is a difficult image processing tas
openaccess.thecvf.com
논문을 읽기 전, 난 이미 transfomer에 대해 접했기 때문에 Style transfer는 transformer를 이용한 기술이라고 생각했다^^,, 하지만, Style transfer는 모델을 뜻하는 것이 아니라, 어떤 이미지의 Style을 transfer(전이)한다는 맥락에서 붙여진 것이다. 이제 본격적으로 논문으로 들어가 보자.
논문의 초록에서는 이전방식은 'style로부터 image content'를 분리하는 데에서 한계가 있다고 말한다. 쉽게 말해서 style이라는 것이 워낙 추상적이기 때문에, 이를 우리가 이를 이미지로든, 시각적이로든 표현하기가 어려웠다는 것이다. 추가적으로, 논문의 서론에서는 이전방식은 오직 low-level의 이미지 특징들만 style을 transfer 하는 데 사용했다는 점도 한계로써 지적한다. 그렇다면 이러한 limitation을 극복하기 위해서 논문은 어떤 방식을 적용했을까?
기존 object recognization 작업을 통해 훈련된 pretrained model 사용
먼저 논문에서 제시하는 모델을 살펴보면, 기존 object recognization작업을 통해 이미 훈련된 VGGNet을 사용한다. (여기서 classfier 하는 부분은 사용하지 않음.) 그 이유는 'filter의 범용성'에 있다. pretrained 된 모델의 필터는 low layer에는 이미지의 가로선, 대각선, 색 등에 반응하는 필터도 존재하고, layer가 깊어질수록 복잡하고 추상적인 이미지의 패턴에 반응할 수 있는 필터도 존재한다. 이러한 필터는 단순히 image recognization 작업에서만 제한되는 것이 아니라, '어떠한 이미지 작업을 하더라도 적용할 수 있는 필터' 들이다. 이러한 이유에서 논문에서는 Content와 Style을 이미지에서 뽑아내기 위해서 모두 pretrained 된 model을 활용한다.
이제 본론으로 돌아와서 앞서 언급한 limitation을 극복했는지 알아보자.
논문은 Content representation과 Style representation에 대해서 차례로 정의한다. 먼저 Content representation에서 Content는 우리가 style을 transfer 할 이미지의 content를 가리킨다. 논문은 이러한 이미지의 content를 뽑아내기 위해, 이미지를 pretrained model에 넣고, higher layer에서 출력하는 filter responses를 Content representation으로 활용한다고 말한다. 여기서 higher layer를 굳이 사용하는 이유는 실험적으로 더 잘 되었기 때문이란 것을 알 수 있었다.
그리고 논문의 핵심인 Style representation에서 Style은 correlation between the different filter responses라고 정의하면서, 이는 Gram 행렬을 통해 이를 수학적으로 계산한다고 설명한다. 특히 흥미로운 점은 이렇게 Style을 뽑아내는 것을 low layer에서 higher layer까지 모두 뽑아낸다. 이는 층을 거치면서 얻게 되는 representation이 달라지기 때문이다.
이처럼 논문에서 제시하는 방식은 기존의 limiatation이었던 style을 위와 같이 정의함으로써, 좀 더 가시적으로 표현하고 나아가 neural network를 사용할 수 있게 해 주었다고 low level에서 higher level에 이르기까지 style을 모두 뽑아낼 수 있게 되었다.
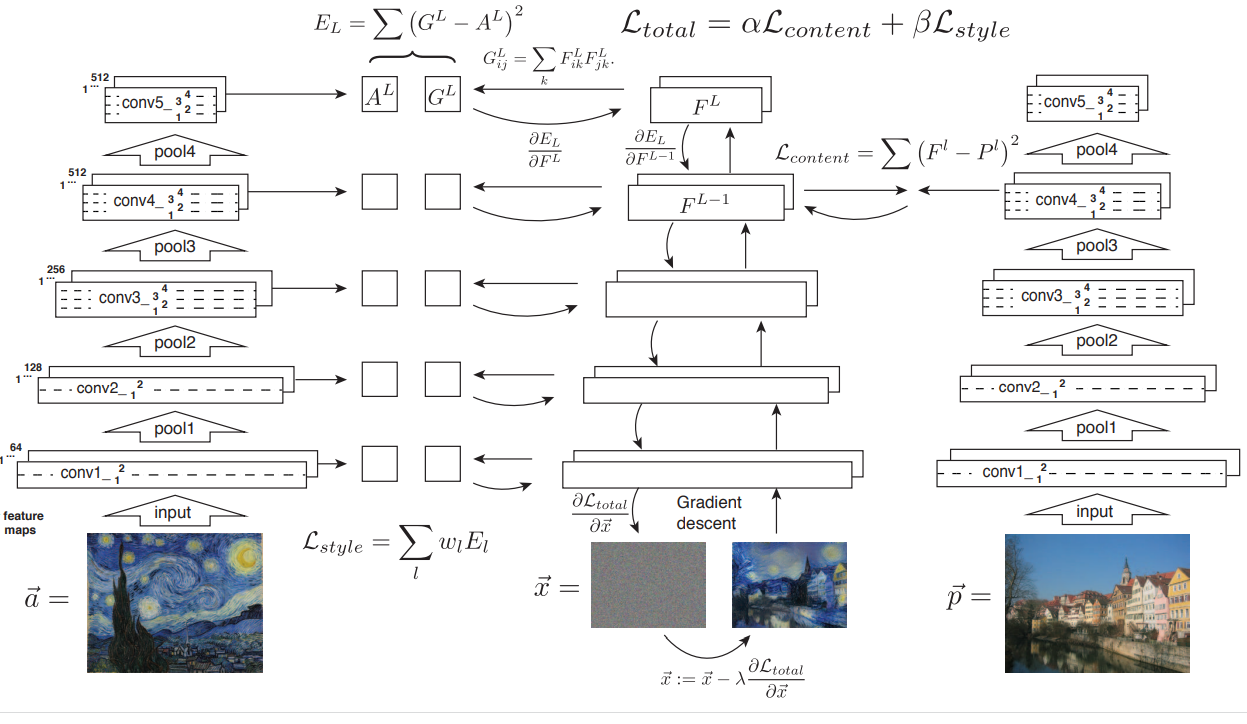
지금부터는 논문에서 제시한 모델 사진을 가지고 설명해보겠다. 그림에서 볼 수 있듯, 크게 3가지 기둥(?)이 있다. 왼쪽 기둥은 style을 뽑아내는 기둥이고, 오른쪽 기둥은 content를 뽑아내는 기둥이다. 그리고 가운데 기둥은 우리가 최종적으로 얻고자 하는 이미지(style+content)를 얻기 위한 기둥이다. 세 기둥 모두 같은 구조의 pretrained model을 사용한다. 이제 이 복잡해 보이는 모델의 loss는 어떻게 계산되는지 보자.
먼저 Style의 loss, Lstyle은 다음과 같이 계산된다.
-> style 기둥(왼쪽 기둥)의 모든 layer에서 각각 그람 행렬을 통해 뽑아낸 style은 같은 방식으로 계산한, 가운데 기둥의 style과 MSEloss를 계산한다. 이를 가중합 한다.
그리고 Content의 loss, Lcontent는 다음과 같이 계산된다.
-> content 기둥(오른쪽 기둥)의 특정 layer(위 사진에서는 conv4)까지 거친 후 나온 filter response와 같은 방식으로 뽑아낸 content와 MSEloss 계산
최종적으로 모델의 loss, Ltotal은 위 두 loss를 각각의 가중치를 곱해서 선형 결합한 형태이다.
논문에서는 이러한 가중치를 어떻게 조정하느냐에 따라 최종적으로 얻는 이미지의 형태가 달라진다고 설명한다. 직관적으로도 알 수 있듯이, content에 가중치가 큰 경우, style에 비해 content를 많이 반영한 그림이 나올 것이다.
추가로, optimizer는 L-BFG를 사용했을 때 가장 성능이 잘 나왔다는 것을 알 수 있었다.
마지막으로 논문의 Discussion 파트에서 이러한 기술의 몇 가지 한계점을 제시한다. 첫 번째는 이미지의 해상도에 관한 것이었다. 즉, 이미지의 해상도에 모델 학습에 소요되는 시간이 크게 의존한다는 점이다. 이 점은 앞으로 발전하는 기술로써 해결할 수 있다고 설명한다. 두 번째는 noise에 관한 것으로, 특히 photo와 같은 실제 이미지들에 대해서는 이러한 noise는 중요한 issue다. 이 역시 후처리를 통해 어느 정도는 해결할 수 있다고 말한다. 마지막으로 최종적으로 도출된 이미지가 content와 style을 완전하게 분리해서 가져왔는가에 대한 객관적인 척도가 없었다는 점이다. 즉 반 고흐 그림 '별이 빛나는 밤'의 style을 가져올 때, 이 그림의 별과 나무 같은 content를 제외한 style만을 온전하게 가져왔는지에 대해 객관적인 판단 기준이 없다는 점이다. 논문에서는 이를 단순히 눈으로 확인하면서 판단했다고 말한다.
이번 논문을 읽으면서 가장 크게 와닿았던 점은 인간의 시각 system이 엄청난 추론 능력을 가지고 있다는 점과, 이러한 system을 컴퓨터, 딥러닝으로써 구현하는 과정이 쉽지 않다는 점이었다. 가령 논문에서 다루었던 style transfer을 보면 우리는 몇 초안에 어떤 이미지의 style을 곧바로 다른 이미지에 입힌 이미지를 쉽게 상상할 수 있다. 하지만, 이를 딥러닝으로써 구현하기 위해서는 우리가 직관적으로 잘 아는 content와 style을 수학적인 언어로 표현을 해야 한다.
이렇게 컴퓨터 비전이 어렵고, 연구가 필요한 부분이 많은 이유에 대해 생각해보면 볼수록, 그만큼 우리 인간의 시각, 눈이 정교하고 굉장하다는 것을 깨닫게 된다.
참고로 이번 논문에서 제시하고 있는 모델을 책을 참고해서 직접 구현해보았다. 아래 나의 깃헙 주소에서 확인할 수 있다.
https://github.com/ChoiDae1/Pytorch_Study/blob/main/Ch8.ipynb
실제 출력 화면을 보면 더 재밌다.
'Paper review' 카테고리의 다른 글
| [Paper review] Vision Transfomers for Dense Prediction (0) | 2022.01.18 |
|---|---|
| [Paper review] End-to-End Object Detection with Transfomers (0) | 2022.01.18 |
| [Paper review] Mask R-CNN (0) | 2022.01.12 |
| [Paper review] MLP-Mixer An all-MLP Architecture for Vision (0) | 2022.01.08 |
| [Paper review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2022.01.06 |


댓글 영역