고정 헤더 영역
상세 컨텐츠
본문
오늘 리뷰하고자 하는 논문은 GIRAFFE, StyleNeRF와 같은 3D Generator 계열의 모델 중 하나인 EG3D이다. 여기서 3D Generator는 3D-aware한 이미지를 생성하는 모델이라고 생각하면된다. 흔히 3D Generator는 3D-aware한 이미지를 만들어 내기 위해서 3차원 공간에서 ray sampling을 통한 Neural Rendering 과정을 거친다. (이 부분이 잘 이해가 되지 않는다면, NeRF 포스팅을 보고 오길 바란다) 그리고 Rendering을 하기전 ray sampling한 포인트들에 대응하는 color, density 값을 뽑아야 하는데, 이를 뽑는 방식에 따라 크게 세가지로 나뉜다.

먼저 Voxel 기반의 Explicit한 방법이다. 이 방법은 Implicit한 방법에 비해 빠르지만, memory overhead와 복잡한 scene에 대해서 표현하기 힘들다. 두번째는 Implicit한 방법이다. NeRF가 대표적인 방법으로, Position과 Direction을 input으로 받아서 FC Layer를 거침으로써 color와 density를 뽑는다. 위 그림을 보면 알 수 있지만 많은 FC Layer 층을 거쳐야 하기 때문에 느리다. 마지막으로 위 두가지를 적절하게 혼합한 Hybrid 방법으로, 이 논문에서 제시하는 방법도 여기에 속한다.
논문에서 제시하는 EG3D는 앞서 설명했듯이 Hybrid 방법을 사용함과 더불어, dual dicrimination, pose conditioning과 같은 다양한 방법을 사용함으로써, 3D-aware한 Image 생성에 있어서 SOTA를 달성했다. 실제 성능을 눈으로 보면 더 놀라운데, 포스팅 하단에 EG3D 공식 웹페이지 주소를 첨부해놨으니 꼭 한번 보길 바란다.
이제 본론으로 돌아와서 EG3D에 적용된 구조와 방법론에 대해서 하나씩 살펴보자.
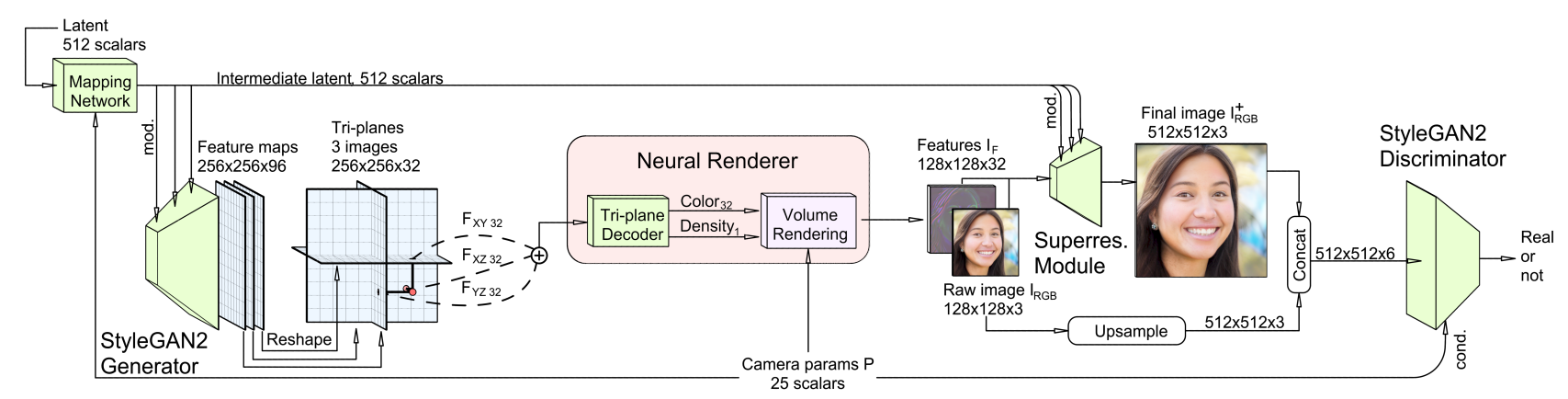
위 사진이 EG3D의 전체적인 구조이다. 먼저 가장 눈에 띄는 것이 StyleGAN2 Generator의 Feature(256*256*96)을 뽑아내서 이를 3개로 분할해 각각 plane(Tri-planes)로 사용했다는 점이다. 이게 EG3D가 제시하는 Hybird 방식의 핵심이다. ray sampling은 이러한 Tri-plane 상에서 진행된다. sampling 후 각 plane으로 projection이 진행되고, 이를 summation한 뒤 하나의 최종적인 feature가 나오면 이를 fc layer를 통과 시켜서 sampling한 point에 대한 color와 density를 뽑을 수 있다. 이렇게 Hybrid 방식을 사용함으로써 계산상의 efficiency와 scene에 대한 expressiveness를 모두 잡을 수 있었다고 한다.
sampling한 point들에 대해서 color와 density값이 모두 나오면, 이를 Rendering한다. 이 때 NeRF와 같은 모델은 rendering을 거치게 되면, 곧바로 이미지의 한 픽셀에 대한 rgb값이 나오게 된다. 하지만 이러한 방식을 사용해 고해상도의 이미지를 만들어내려면 high computing cost가 요구되기 때문에, 논문에서는 저해상도의 feature volume을 하나 만들어 낸 뒤에 이를 upsampling하는 방식으로 최종적인 이미지를 만든다. (이 방식은 GIRAFFE에서 처음으로 제시한 방식이라고 알고 있다.) 위 그림에서 보는 것처럼 Feature I(F)가 Rendering한 뒤 만들어지는 feature volume(128*128*32)이다. 이 feature volume은 Super resolution Module을 거치게 되면서 256*256 혹은 512*512 해상도의 이미지로 만들어 진다. Super reslution Module은 StyleGAN2의 convolution block 2개로 이루어져있다고 한다.
지금까지 전체적인 EG3D의 구조를 살펴보았다. 이제 이 모델에 적용된 훈련방식과 추가적인 방법론에 대해서 살펴보자. 우리가 GAN을 훈련시킬때 흔히 Discriminator를 사용한다. EG3D도 GAN과 같은 Generator이기에, Discriminator를 통과하여 훈련한다. 하지만 이와 약간 다른 Dual discriminator를 사용한다. Dual discriminator는 최종적으로 뽑아낸 이미지와 feature volume의 첫 3개의 channel을 upsampling 한 이미지를 concat하여 discriminator에 통과시키는 방식이다. 논문에서는 이러한 방식이 rendering이 real image feature distribution과 잘 matching될 수 있게 만듬과 동시에 최종 이미지가 rendering과 consistency가 유지되도록 만들어준다고 한다. 추가적으로 discriminator에는 training image에 대응하는 Camera parameter도 condition으로 넣어줌으로써, Discriminator가 Camera pose에 대해서도 잘 aware할 수 있도록 했다.
Camera parameter 얘기가 나와서 논문에서 제시한 또다른 방법론을 설명하면, 논문에서는 Camera parameter를 세가지 부분에 사용한다. 첫번째가 앞서 언급한 Dual Discriminator이고, 두번째가 Rendering시 ray sampling을 위해 사용된다. 마지막으로 처음에 StyleGAN2의 mapping network의 condition으로 사용된다. 논문에서는 특히 mapping network에 넣어줌으로써, pose와 other attribute를 decoupling을 유도하였다고 한다.
지금까지 EG3D의 구조와 핵심 방법론들에 대해서 알아봤다. 이제 성능을 한번 확인해보자.

위 그림을 보면 알겠지만 다른 모델들에 비해서 3D-aware한 이미지를 EG3D는 생성할 수 있다는 것을 알 수 있다. (회색 형상이 잘 나올수록, 3D-aware하다.)

수치적인 결과를 확인해도 FFHQ와 Cats 데이터섹에서 SOTA의 성능을 낸다는 것을 알 수 있다.
이외에도 StyleGAN2 backbone으로 사용했기 때문에, 흔히 사용하는 latent Inversion, latent Interpolation이 모두 가능하다. 정말 흥미로운 모델임은 확실한 것 같다. 논문에서는 한계점도 제시하고 있었는데, 첫번째는 사람의 이빨과 같은 다소 finer detail에 대해서는 약간의 부족함이 있을 수 있다는 점이고 두번째는 모델을 훈련하기 위해서는 dataset에 대한 camera pose에 대한 knowledge가 있어야 한다는 점이다. 그리고 마지막으로 pose와 apperance를 conditioning을 통해 어느정도 해소하려고 시도했지만, 여전히 완벽하게 disentangle하지는 못했다는 점이다.
이번 논문을 읽으면서 어떻게 보면 현재 가장 좋은 성능을 내는 3D Generator는 어떤 구조와 원리를 사용하는지 배울 수 있었다. 특히 학부연구생으로 활동하면서 현재 이 모델을 사용한 연구를 진행하고 있어서 조금 더 꼼꼼히 읽은것같다.
아래는 논문링크와 공식 웹사이트이다. 꼭 한번 읽어보고 들어가서 결과를 확인하길 바란다.
https://arxiv.org/abs/2112.07945
Efficient Geometry-aware 3D Generative Adversarial Networks
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D
arxiv.org
https://nvlabs.github.io/eg3d/
EG3D: Efficient Geometry-aware 3D GANs
EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks Abstract Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing
nvlabs.github.io


댓글 영역