고정 헤더 영역
상세 컨텐츠
본문
오늘 포스팅은 KUBIG 정규세션 스터디의 일환으로 "Interpreting the Regression Equation"에 대해 발표를 목적으로 작성하게 됐다. 스터디는 "Practical Statistics for Data Scientists" 라는 도서를 공부하고 한 주간 특정 부분을 맡아서 발표를 하는 식으로 진행된다. 따라서 지금 작성하는 포스팅의 모든 내용은 모두 이 책에 기반으로 작성되었음을 알린다.
우리는 회귀분석을 설계하고, 분석결과를 보면서 단순히 설계한 회귀방정식이 종속변수값을 얼마나 잘 예측하는지도 확인해야하지만, 그외 다른 요인들(독립변수들 사이의 상관관계 etc)등도 종합적으로 고려해야 한다. 특히 데이터가 한정돼있고, 전통적인 통계학에서는 이러한 요인들을 주의깊게 고려하는 것이 특히 중요하다. 이번 포스팅에서는 회귀분석을 설계하고, 분석하는 과정에서 고려해야 할 다양한 요인들에 대해서 설명할 것이다.
Correlated variables and Multicollinearity
회귀방정식은 두가지 부분, 독립변수들과 종속변수로 나뉜다. 여기서 독립변수라는 이름에서 알 수 있듯이 종속변수를 예측하기 위한 변수들은 서로 독립적일 필요가 있다. 만약 이러한 독립변수들이 서로 correlated 될 경우, 회귀방정식의 계수들을 해석하기에 어려움이 생긴다. 완벽하게 독립적인 변수들로 이루어져 있는 회귀방정식의 경우 독립변수 앞 계수는 종속변수에 끼치는 영향으로 해석할 수 있지만, 독립변수들이 서로 correlated된 경우, 계수 자체가 다른 독립변수들의 영향을 받기 때문에 해석에 어려움이 생기는 것이다.
이러한 맥락에서 회귀분석을 설계하는 과정에서 독립변수 중 Correlated variable을 확인하는 과정은 중요하다. 이러한 개념과 더불어 자주 등장하는 개념이 Multicollinearity, 다중공산성이다. 다중공산성은 쉽게 설명하면, Correlated variable의 extreme case이다. 즉 독립변수들 사이의 아주 강한 상관관계가 일어나는 경우로, 변수 자체가 다른 변수들의 선형결합으로 표현되는 경우가 있다.
보통 이러한 다중공산성은 독립변수가 (1) 여러번 회귀방정식에 실수 포함되거나, (2) 더미변수를 p-1개 써야 하는데, p개 쓰는 경우, (3) 두 변수가 강한 상관관계를 보이는 경우 발생한다.
다중공산성은 보통 VIF라 하는 분산팽창요인을 계산하여, 이 값이 10을 넘을 경우 다중공산성이 존재한다고 진단한다.
참고로, tree, clustering 등과 같이 nonlinear regression 방법을 사용할때는 이러한 다중공산성 자체가 문제가 되지는 않는다고 한다.
Confounding Variables
Confounding variable, 교란변수는 말그대로 회귀분석을 교란시키는 변수이다. 이 변수는 회귀방정식에는 포함되지 않았지만, 독립변수, 종속변수에는 영향을 미치는 변수이다. 가령 학생들의 공부시간과 성적사이의 회귀분석을 진행할때, 학생들의 기존 성취도가 교란변수가 될 수 있다. 이러한 교란변수는 회귀방정식의 인과관계를 실제효과보다 크거나 작은것으로 보이게 한다. 이를 통제하기 위해서는 실험을 설계할때부터, 관련 변인을 잘 통제해야하거나 변수를 회귀방정식에 넣어야 한다.
Interactions and Main Effects
회귀방정식을 설계할때, 독립변수 각각이 종속변수에 영향을 주는 Main effect는 물론 독립변수 여러개가 상호작용함으로써 종속변수에 영향을 주는 Interactions도 고려해야 한다. 이러한 Interations 가령, 시너지 효과 등이 존재할때 반드시 회귀방정식에서 고려가 돼야한다. 실제로 회귀방정식에 Interaction term을 넣을지는 challenge한 문제인데, 보통 다음과 같은 접근방법들을 통해 활용된다.
(1) prior knowledge (2) stepwise selection (3) panalized regression(자동으로 가능한 large set of interaction terms에 fitting하는 효과) (4) tree model (자동으로 최적의 interaction term을 찾는다)
지금까지 설명한 내용들은 거의 대부분 회귀방정식을 설계하는 과정에서 정확하게 분석, 해석돼야 하는 부분이다. 이제부터는 회귀분석을 진행하고 나서 해석, 분석해야하는 요인들에 대해서 설명하고자 한다.
Outliers
Outliers는 실제 y값과 회귀분석을 통해 예측된 y값이 많은 차이를 보이는 값을 말한다. 이상치와 비이상치를 구분짓는 명확한 통계학적 이론은 없다. 하지만, 얼마나 많은 차이를 보이는지 확인하는 기준은 존재하는데, 회귀분석에서는 주로 standardized residual이 사용된다. 이는 회귀분석 line으로 부터, 얼마의 표준오차만큼 떨어져있는지로 해석한다. 이러한 outlier는 많은 양의 데이터가 존재하는 데이터 사이언스에서, 회귀모델을 fitting 시킬때 문제가 되지는 않는다고 한다.
Influential values
이 값이 포함되느냐 안되느냐에 따라 회귀방정식에 있어서 큰 변화를 가져오는 값을 Influential value, 영향치라고 한다. 이러한 영향치는 통계학적으로 high leverage on regression이라고 표현된다. 아래 그림을 보자.

파란색라인은 오른쪽 상단 위 하나의 value가 포함될 경우, 분석되는 회귀선을 보여주고, 빨간색점선은 이 value가 포함되지 않을 경우, 분석되는 회귀선을 보여준다. value값이 포함되냐 안 포함되냐에 따라 엄청난 차이를 보인다는 것을 확인할 수 있다. 이와같은 영향치는 hat-value, Cook's distance를 통해 판별한다.
Hetoeroskedasticity
Hetoeroskedasticity, 이분산은 말그대로 residual의 variance가 predicted value에 따라 일정하지 않고, 다른 현상을 말한다. 아래 그림을 보자.

x축이 predicted value이고 y축이 residual의 절댓값인데, 회색 부분의 width자체가 일정하지 않고, 들쭉날쭉한다는 것을 알수 있다. 이러한 경우를 이분산이라고 말하고, 이는 회귀모델이 incomplete하다는 것을 의미한다. 위 그래프에서는 predicted value가 작고, 클때 residual이 상대적으로 크므로 이부분에 대한 추가적인 분석이 필요하다.
Partial Residual plots
Partial Residual plot은 추정된 fitting에서, 하나의 독립변수와 종속변수 사아의 관계가 얼마나 잘 표현되는지 분석하기 위한 tool이다. 방법은 간단하다.

full model의 residual값에 확인하고자 하는 독립변수의 term을 더하면 된다. 그리고 독립변수의 값을 변화시켜보면서 residual의 값을 확인하면 된다.
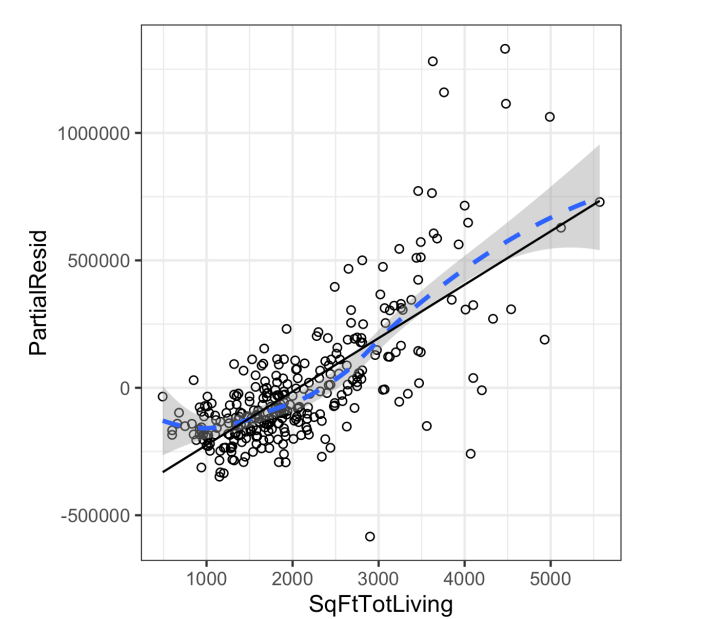
위 그림이 patialresidualplot을 나타내는것이다. 그래프에서 파란선이 partial residual을 통해, 실제로 독립변수와 종속변수와의 관계를 표현한것이라 해석하면 된다. 선형회귀를 할경우 검정색라인으로 표현되는데, 실제 관계를 표현하기에는 한계가 있다는것으로 확인할 수 있다. 이 경우 고차항이 필요하다.
'KUBIG' 카테고리의 다른 글
| [2022-1 KUBIG 정규세션] Boosting (0) | 2022.07.23 |
|---|---|
| [2022-1 KUBIG 정규세션] Statistical Significance and p-Values, and t-test 추가설명 (0) | 2022.04.14 |
| [2022-2 KUBIG 정규세션] Statistical Significance and p-values + t-Test (0) | 2022.03.31 |
| [2022-1 KUBIG 정규세션] Sampling Distribution of a Statistic 추가설명 (0) | 2022.03.24 |
| [2022-1 KUBIG 정규세션] Sampling Distribution of a Statistic 발표준비 (0) | 2022.03.17 |


댓글 영역